研究の問い / 技術の機能 Question
複数人が同時に映る会話映像から、マイクなしに誰が話しているかをリアルタイムで判定できるか。人物追跡と口元の動作解析を組み合わせ、グループインタビューや議事録自動生成への応用を見据えた発話話者検出システムの開発に取り組みました。映像だけで「誰が話しているか」を正確に推定できれば、分析の幅は大きく広がります。
話者検出アルゴリズムとは
話者検出アルゴリズムとは、会話映像から顔追跡と口の開閉検知を組み合わせ、発話者を自動推定する処理基盤です。音声ラベルなしに映像のみから発話者情報を取得できるため、後続解析の入力として広く活用できます。
プロジェクト概要 Project Overview

グループ会話における話者を正確に検出するためのアルゴリズム基盤を構築した事例です。本プロジェクトでは、顔特徴点追跡と口の開閉検知ディープラーニングモデルを統合し、映像内の発話者を自動的に推定する仕組みをオルチェが開発しました。
-
目的
-
映像から話者を自動推定できる処理基盤を構築する
-
手法1
-
顔特徴点追跡(人物ごとの位置・動き・口元を取得)
-
手法2
-
口の開閉検知ディープラーニングモデル(大量ビデオで学習)
-
統合出力
-
グループ会話における話者推定結果
背景・課題 Background
会話データを解析する際、「誰が話しているか」という情報は重要な要素です。特に複数人が同時に存在する環境では、発話者情報を安定的に取得できる仕組みがあることで、後続の解析や応用の幅が大きく広がります。
-
01
複数人が映る映像から誰が話しているかを自動判定する手法が限られていました。
-
02
音声と映像の紐づけの課題
音声のみで話者を判定する手法では、映像解析との統合に制約がありました。
-
03
後続解析の入力データ不足
会話解析・関係性評価などの研究を進めるには、話者ラベル付きデータの自動生成基盤が必要でした。
アプローチ Approach
人物追跡と発話検知を分離し、それぞれを高精度化したうえで統合する二段構造のアルゴリズムを設計しました。顔の追跡によって人物ごとの位置・動きを安定的に取得し、口の開閉検知モデルによって発話瞬間を推定する構造です。
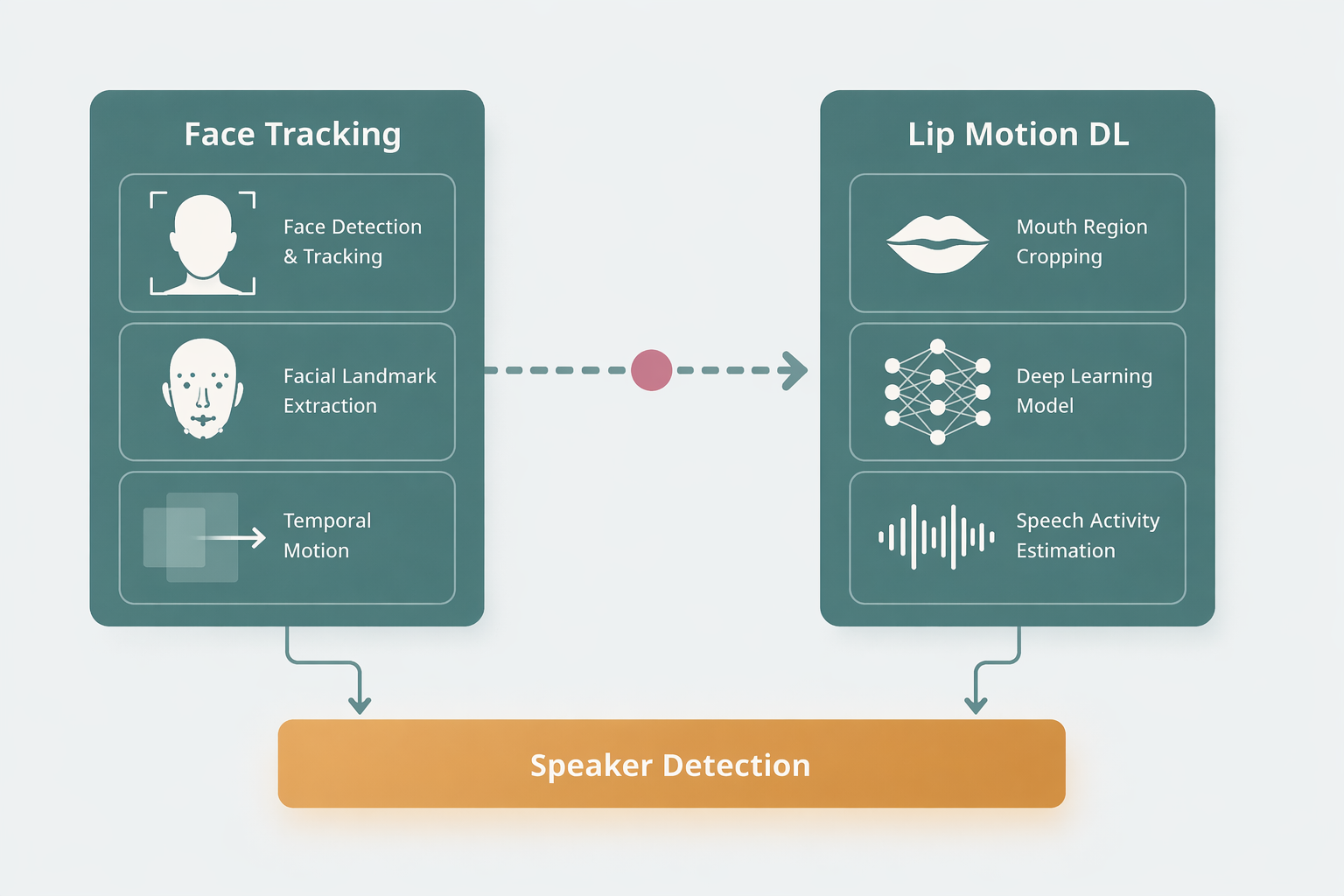
二段構造アルゴリズム
-
顔特徴点追跡 Face Landmark Tracking
- 映像内の顔を連続追跡
- 目・鼻・口などの特徴点を同定
- 人物ごとの動きと口元動作を取得
人物ごとの位置・動きを安定取得し、発話検知モデルへの入力データを生成します。

approach-face-tracking.png -
口の開閉検知モデル Lip Motion Detection
- 顔特徴点追跡データを入力
- 大量のビデオデータで学習したディープラーニングモデル
- 口の開閉動作から発話瞬間を推定
大規模学習済みモデルにより、口元の微細な動きから発話タイミングを高精度に推定します。
approach-lip-detection.png
得られた知見・成果 Results
本プロジェクトにより、人物追跡処理系・口元動作検知モデル・統合型話者推定アルゴリズムからなる話者検出基盤を構築しました。映像ベースで発話者を推定するための技術土台を整備しました。
-
01
二段構造アルゴリズムを確立
追跡と検知を分離・統合することで、安定した話者推定が可能な処理基盤を構築しました。
-
02
映像のみでの話者判定を実現
音声ラベルなしに映像データだけから発話者を自動推定できる仕組みを整備しました。
-
03
後続解析への汎用基盤を提供
会話解析・関係性評価など、多様な研究・実務プロジェクトで再利用可能な基盤を構築しました。
位置付け・展望 Position & Outlook
マルチモーダル会話解析の基盤技術として
本基盤は、会話映像を扱う多様な研究・実務プロジェクトで再利用可能な汎用技術です。オルチェが提供する話者検出基盤は、会議記録・映像コンテンツ解析・ヘルスケア分野での会話支援など、幅広い応用への入口となります。
- 会議記録・議事録の自動生成支援
- 映像コンテンツの話者分離・字幕生成
- ヘルスケア分野での会話支援・コミュニケーション評価

誰もが、会話から取り残されない社会へ。
オルチェは、一人ひとりの声を正しく捉える技術を通じて、
より多くの人がコミュニケーションに参加できる未来を目指しています。